Introduction to Generative Models
Main types of generative models:
- Autoregressive models
- Variational Autoencoders (VAE)
- Generative Adversarial Networks (GAN)
Issues:
- Autoregressive models are slow because they generate elements sequentially.
- VAEs optimize ELBO instead of true likelihood.
- GANs are powerful but unstable and less effective for tasks like speech generation.
Reference: https://www.youtube.com/watch?v=uXY18nzdSsM
Flow-based Models
Flow-based models optimize the log-likelihood of data pG(x) transformed from a Gaussian distribution π(z):
z→G→x
Objective:
G∗=argmaxG∑i=1mlogpG(xi)
Equivalent to minimizing:
argminG∑imDKL(pdata∥pG)
Flow-based models directly optimize log-likelihood.
Timeline
2014 — NICE
2016 — RealNVP
2018 — Glow
Jacobian Matrix
Given:
x=f(z),z=[z1z2],x=[x1x2]
Jacobian:
Jf=[∂z1∂x1∂z1∂x2∂z2∂x1∂z2∂x2]
Inverse Jacobian:
Jf−1=[∂x1∂z1∂x1∂z2∂x2∂z1∂x2∂z2]
Relationship:
Jf−1⋅Jf=I
Determinant of Jacobian
For an invertible matrix A:
det(A−1)=det(A)1
Thus:
det(Jf−1)=det(Jf)1
Important for computing likelihood via change of variables.
Change of Variable Theorem
If x=f(z):
p(x)∣det(Jf)∣=π(z)
Thus:
p(x)=π(z)∣det(Jf−1)∣
2D Illustration
Picking a small square in z mapped to a deformed region in x gives:
π(z′)=p(x′)det[∂z1∂x1∂z1∂x2∂z2∂x1∂z2∂x2]
Thus:
π(z′)=p(x′)∣det(Jf)∣
New Objective
Using:
pG(x)=π(G−1(x))∣det(JG−1)∣
We obtain:
G∗=argGmaxi=1∑m[logπ(G−1(xi))+log∣det(JG−1)∣]
Why Coupling Layers
Problems:
- High-dimensional Jacobians make determinants expensive.
- Training requires G−1, so G must be invertible and dimension-preserving.
- Need multiple invertible transformations → flows.
Coupling Layers
We apply a sequence of invertible transformations:
zi=G1−1(G2−1(⋯GK−1(xi)))
Density:
pK(xi)=π(zi)h=1∏K∣det(JGh−1)∣
Log density:
logpK(xi)=logπ(zi)+h=1∑Klog∣det(JGh−1)∣
During training we optimize G−1 but use G for generation.
Affine Coupling Layer
To compute G−1:
zi≤d=xi,zi>d=βixi−γi
Determinant:
det(JG)=i=d+1∏Dβi
Image:
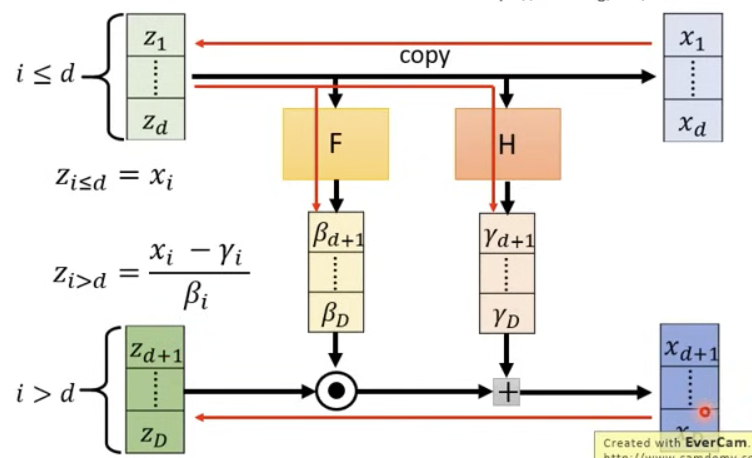
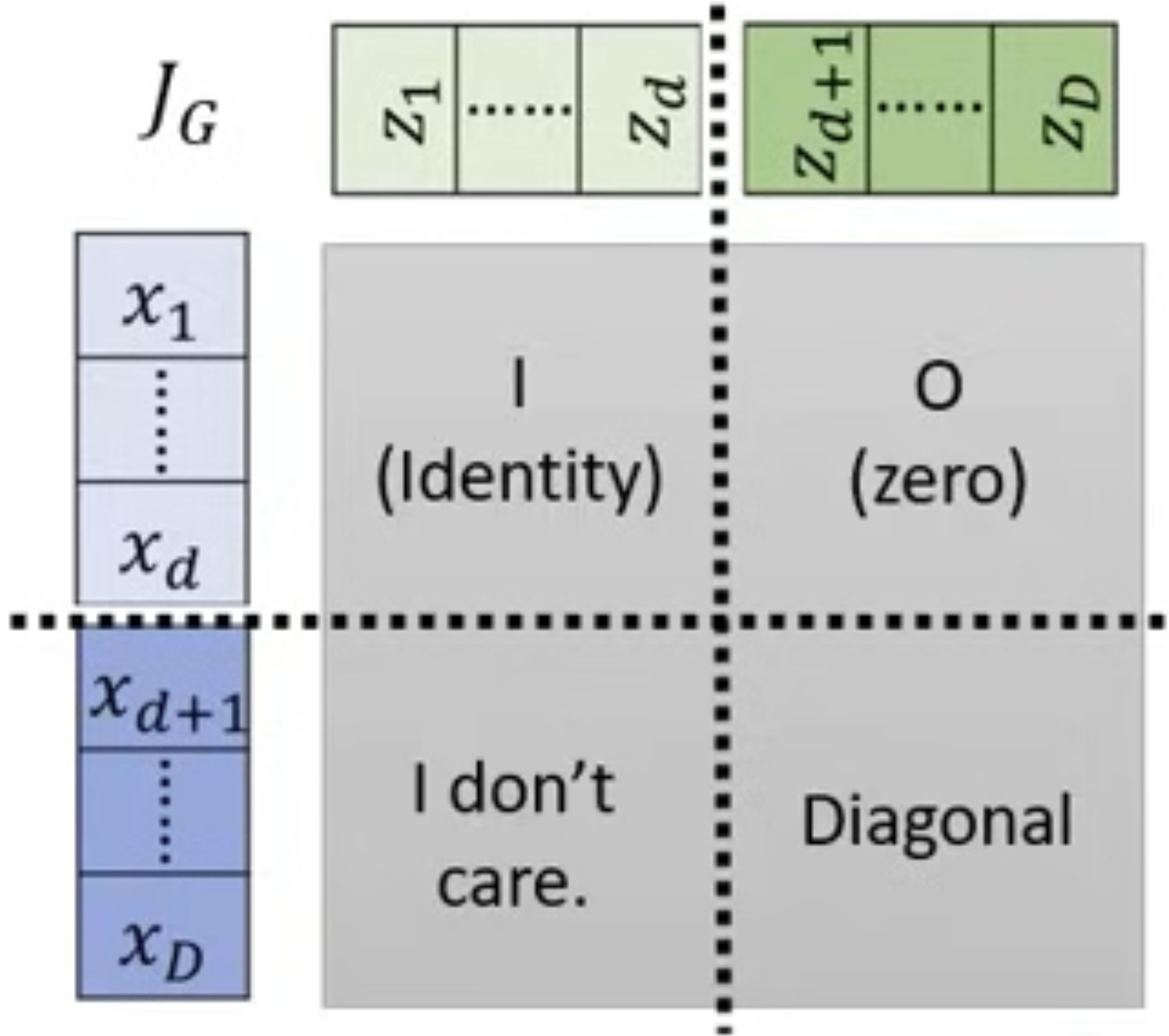
Determinant intuition:
Masking
Two masking strategies:
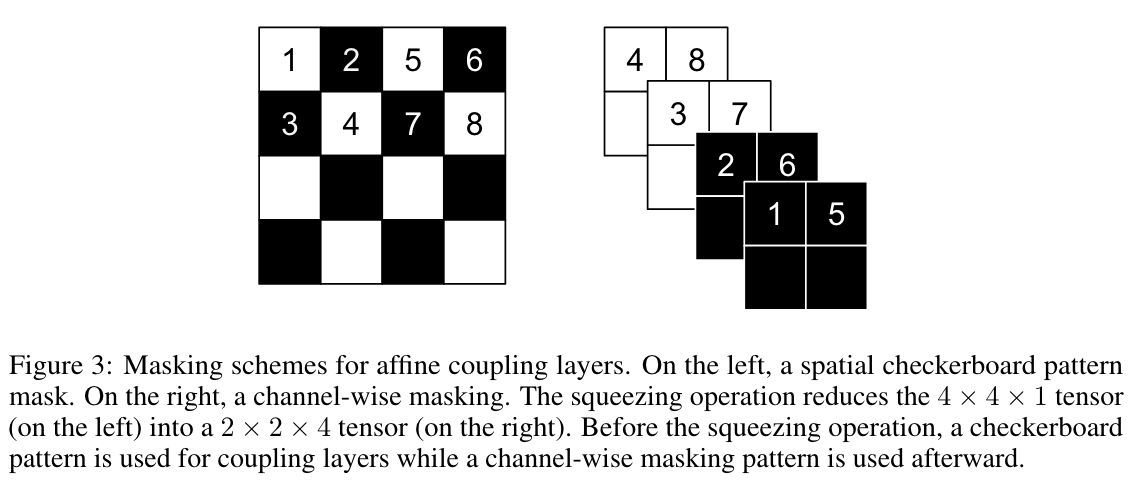
- Checkerboard mask
- Channel-wise masking (using squeezing to increase channels)
Composition of Coupling Layers
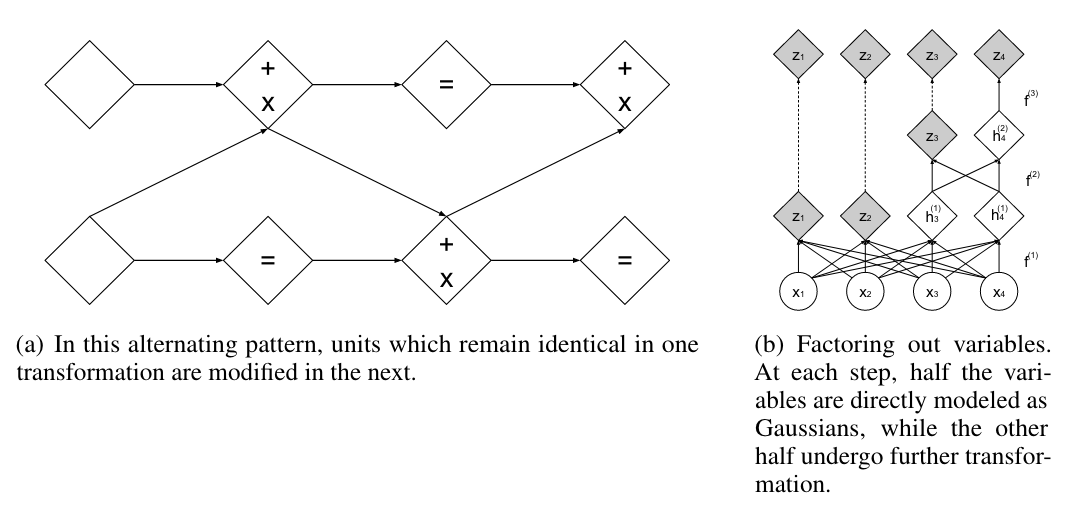
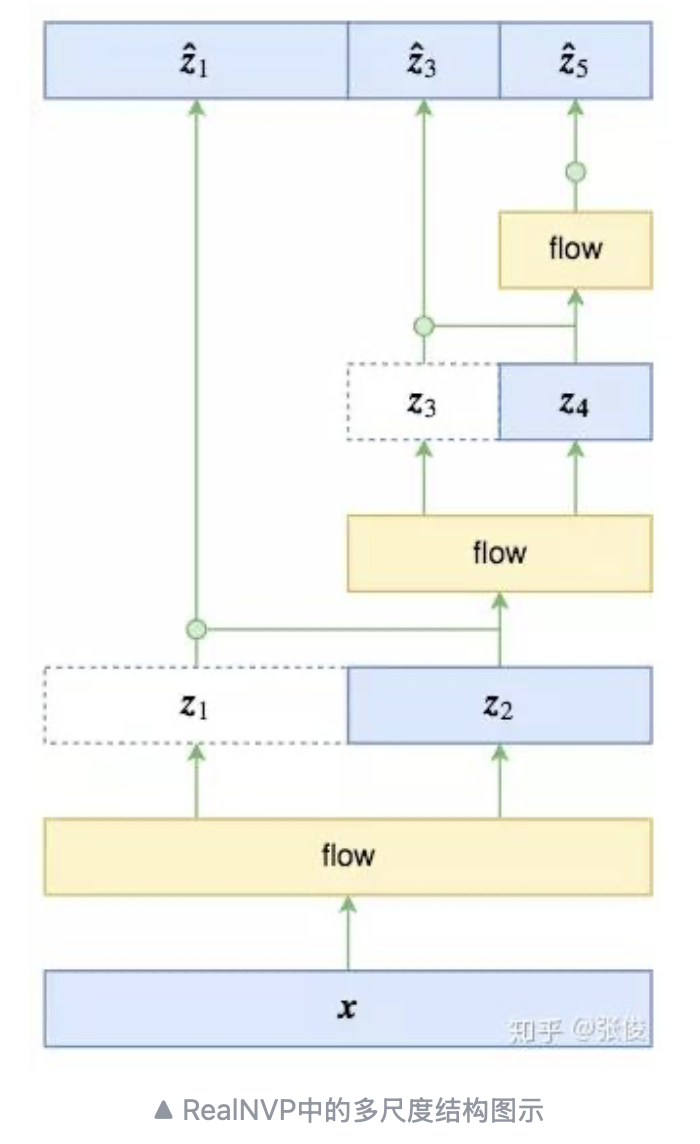
Multi-scale Architecture
Example structure:
- Variables at different scales are not equivalent
- Factorization:
p(z1,z3,z5)=p(z1∣z3,z5)p(z3∣z5)p(z5)
Standardization:
z^1=σ(z2)z1−μ(z2)
Image:
GLOW
Glow architecture:
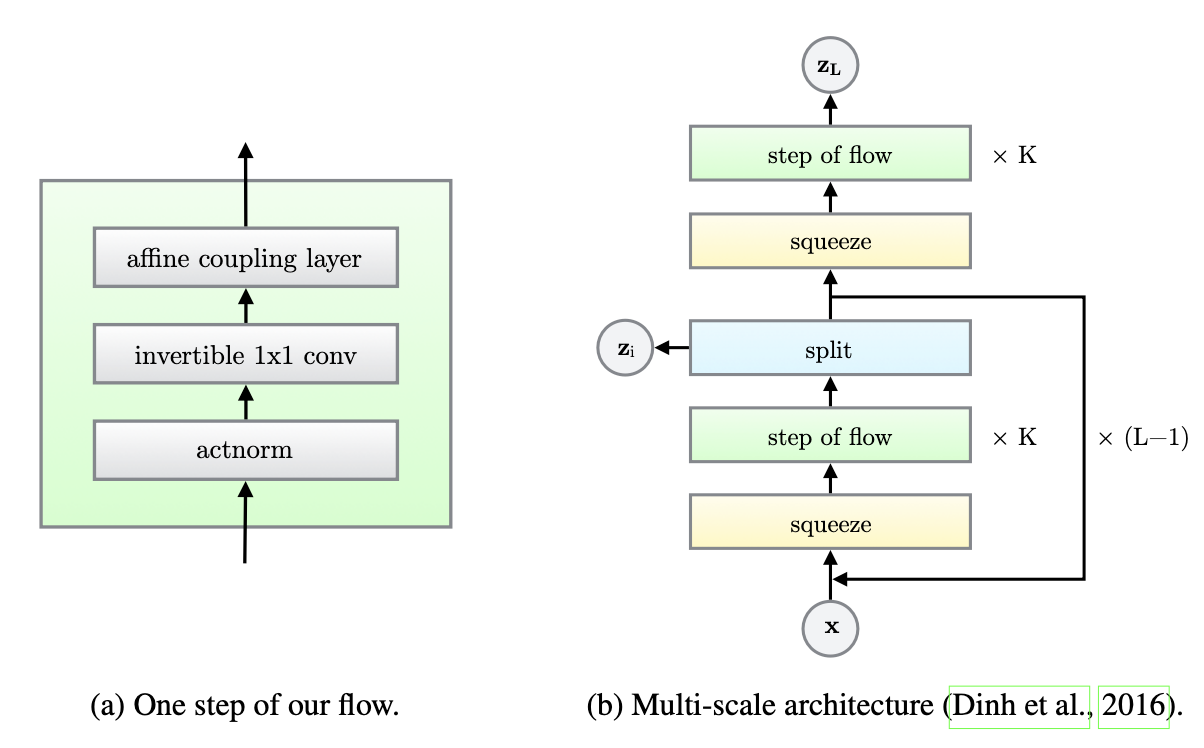
Glow properties:

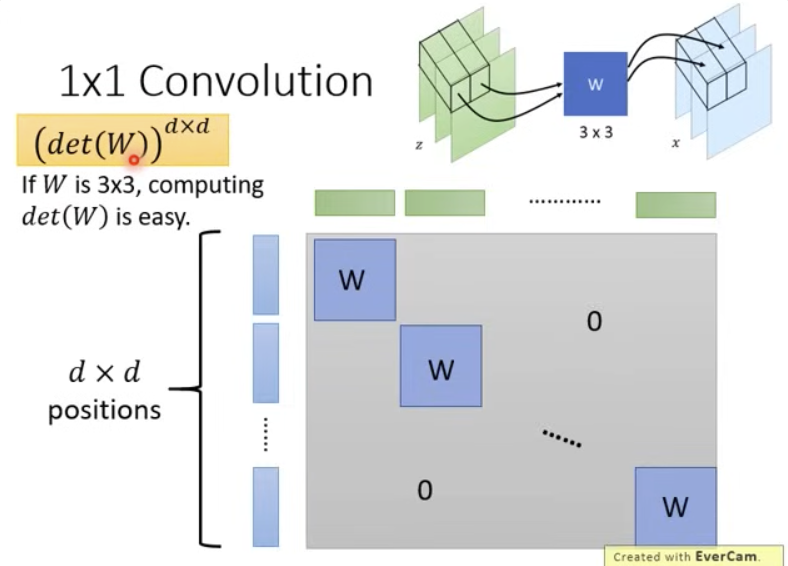
Channel mixing with invertible 3×3 matrix W:
x=Wz
If W is invertible:
Jf=W
Image:
Results
See OpenAI Glow results: https://openai.com/index/glow/

