经典贝叶斯公式:P(Y∣X)=P(X)P(X∣Y)P(Y)- Y:假设 / 隐变量(hypothesis)
- X:观测数据
- P(Y):先验(prior)
- P(X∣Y):似然(likelihood)
- P(Y∣X):后验(posterior)
CNN
- MLP的问题:全连接数据量过大
- 数据特性:图像局部性 locality
- 平移不变性
RNN
时序问题
ht=ϕ(w2ht−1+w1xt+b)
ϕ 的选择:
- 非0: Relu
- 0 - 1: sigmoid (多个结果 softmax)
- -1 - 1: tanh
问题:
w2 累乘,gradient 要么Exploding 要么 Vanishing -> gradient clipping
g=min(1,∣∣g∣∣θ)g
θ is threshold
重要的时序信息没有被区别对待 -> 根据 x 的重要程度调节 h (LSTM)
LSTM
长短期记忆
ht=ϕ(w2ht−1+w1xt+b)
forget
output
input
GRU
Gated Recurrent Unit
forget老记忆:
ht−1′=ftht−1
新记忆:
Ct~=tanh(w2ht−1′+w1xt+b)
最终:
ht=rtht−1+(1−rt)Ct~
Attention
seq2seq information bottleneck
QKV attention
decoder hidden state
Q=w1dht
encoder hidden state
K=w2ehi
similarity
αt=softmax(dkQK)
Ct=αtV
Resnet
深度模型难以训练,vanishing exploding gradient -> normalization
深度越深,能力反而下降,非overfitting -> resnet
H(x)=F(x)+x
element-wise
Shortcut connection
highway networks on LSTM
H(x)=F(x)g(x)+x(1−g(x))
效果不如resnet
维度不一致?
A. zero padding
B. 如果不一致则投影
C. 全部投影
选B
Deeper bottleneck architecture 没有过分 过拟合
h(x)=f(x)+x
y=g(h(x))+h(x)
∂x∂h(x)=∂x∂f(x)+1
∂x∂y=∂h∂g(h)+h+∂x∂f(x)+x=(g′(h)+1)(f′(x)+1)=g′(h)f′(x)+g′(h)+f′(x)+1
1是reserve gradient的关键,故而 highway networks 更差(λn)
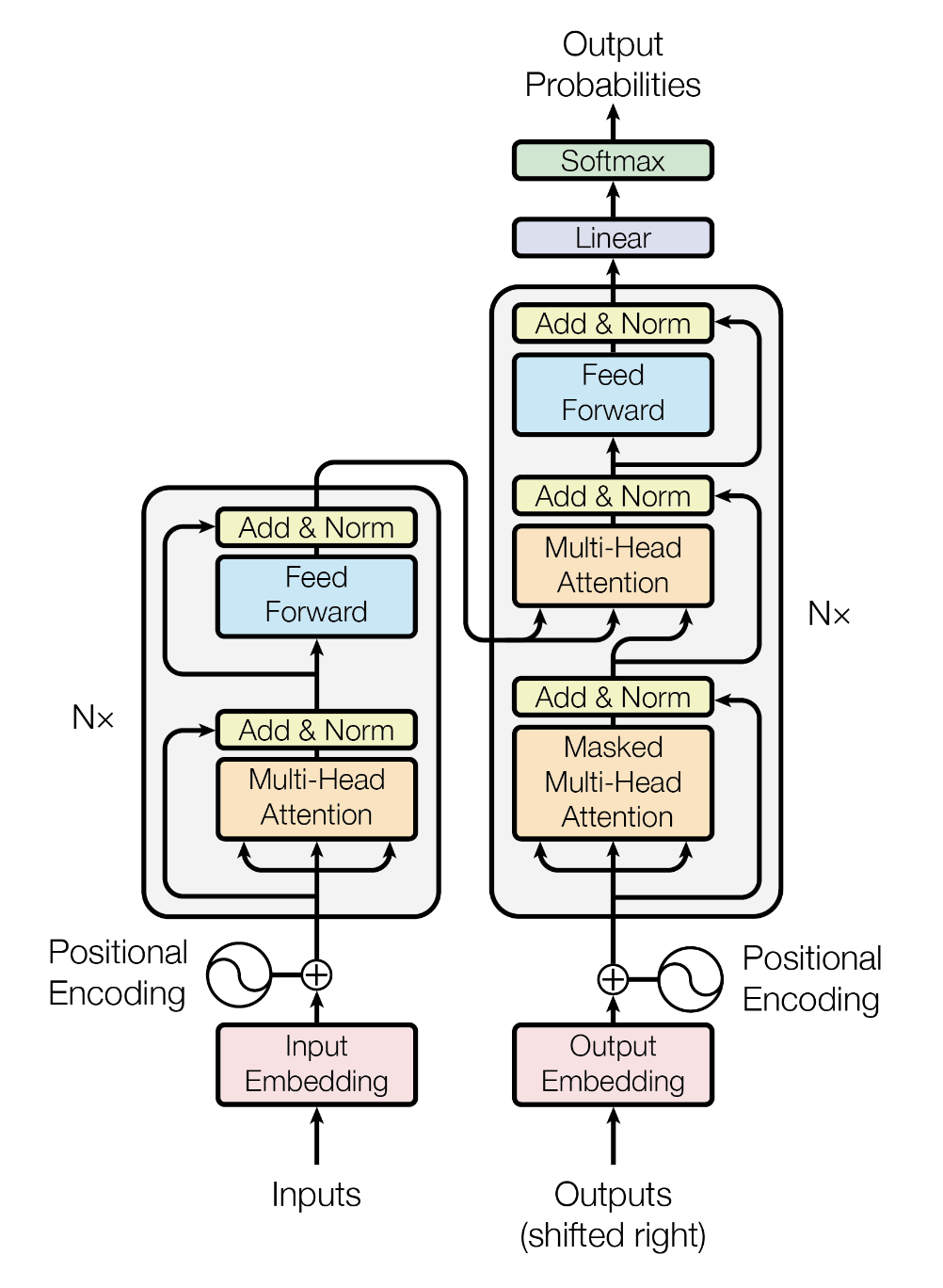 seq2seq sota: RNN - LSTM -GRU
问题:inherently sequential nature
-> parallelization
seq2seq sota: RNN - LSTM -GRU
问题:inherently sequential nature
-> parallelization
Convolutional seq2seq:
self attention
特征提取,自适应,全部上下文,计算简单
multichannel 多个kernel,不同视角
MHA: multi head
Positional Encoding
PE(pos,2i)=sin(10000d2ipos)
不需要计算可学参数
数值大小稳定,不光绝对位置,还有相对位置
element wise 相加真的能被识别吗?
有些head关注位置 BertViz
Decoder
masked attention 设为负无穷,softmax后为0
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|
| Self-Attention | O(n² · d) | O(1) | O(1) |
| Recurrent | O(n · d²) | O(n) | O(n) |
| Convolutional | O(k · n · d²) | O(1) | O(logₖ(n)) |
| Self-Attention (restricted) | O(r · n · d) | O(1) | O(n / r) |
Text to Image
Conditional generation
Classifier based guidance 训练前分,麻烦
Fixed Guidance 训练引入 prompt,diversity 差,遵循指令
Classifier Free 调节 guidance 强度
Classifier-based Guidance
以Diffusion为例:P(xt−1∣xt) -> Guided: P(xt−1∣xt,y)
P(xt−1∣xt,y)=P(y∣xt)P(xt−1∣xt)P(y∣xt−1,xt)=P(y∣xt)P(xt−1∣xt)P(y∣xt−1)=P(xt−1∣xt)elogP(y∣xt−1)−logP(y∣xt)≈P(xt−1∣xt)e(xt−1−xt)⋅∇xtlogP(y∣xt)
P(xt−1∣xt)=N(xt−1;μ(xt),σt2I)∝e−∥xt−1−μ(xt)∥2/2σt2
⇒P(xt−1∣xt,y)∝e2σt2−∥xt−1−μ(xt)∥2+(xt−1−xt)⋅∇xtlogP(y∣xt)∝e−∥xt−1−μ(xt)−σt2⋅∇xtlogP(y∣xt)∥2/2σt2
⇒xt−1=μ(xt)+σt2∇xtlogP(y∣xt)+σtε
Fixed Guidance
以flow-matching为例:
LCFMguided(θ;y)=E(x)∥μtθ(x∣y)−μt(x∣x1)∥2
Classifier-free Guidance (SOTA)
Hierarchical/Cascaded Diffusion
https://arxiv.org/abs/2106.15282
LDM
https://arxiv.org/abs/2112.10752
Stable diffusion
Unet